انتیتی در سئو
شما مطمئناً با عبارت انتیتی Entity یا موجودیت برخورد کردهاید و احتمالاً خیلی دقیق نتوانستهاید معنا و ماهیت آن را به درستی درک کنید.
اما نگران نباشید. من در این مقاله سعی کردم بصورت ساده و قابل فهم مسئله انتیتی در سئو را توضیح بدهم و شما را با موارد زیر آشنا کنم:
انتیتی چیست؟
- انتیتیها مفاهیم یا ویژگیهای خاص و قابل تعریف در مورد یک موضوع هستند. مانند نام، مکان، رنگ، بو، اندازه و…
- انتیتیها برای شناخت دقیق موضوعات توسط گوگل و سایر موتورهای جستجو بزرگ استفاده میشوند.
- انتیتیها بخشی از سیستم معنایی گوگل هستند.
- گوگل با استفاده از انتیتیها میتواند عمیق بودن یا سطحی بودن یک محتوا را تشخیص دهد.
یک مثال از انتیتی
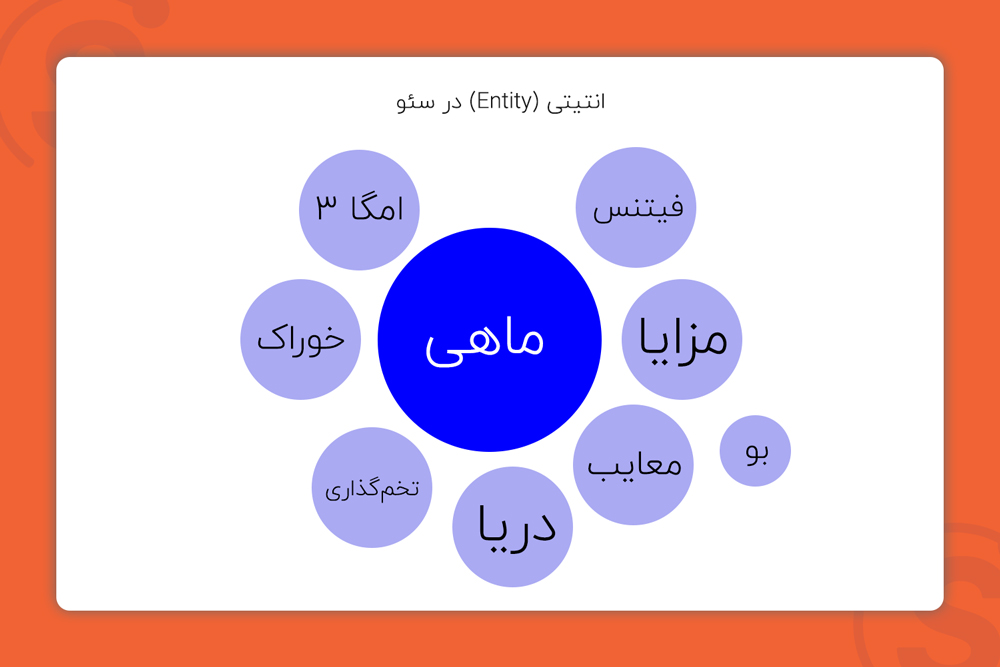
بیاید انتیتی را با یک مثال ساده به شما توضیح دهم. ابتدا عکس زیر را مشاهده کنید.

فرض کنید تاکنون این تصویر را ندیدهاید و نمیدانید ماهیت آن چیست. من برای تعریف این تصویر به شما میگویم:
- یک جانور آبزی و نام آن ماهی است.
- باله داشته و شنا میکند.
- پولک و آب شش دارد.
- محل زندگی آن در آب رودخانهها، دریاچهها، دریاها و اقیانوسها است.
من آمدم و این تصویر را با نام، ویژگیها، محل زندگی به شما معرفی کردم و شما توانستید ماهیت این جانور را بفهمید.
پس Entity یا موجودیت به موضوع یا یک چیزی منحصر به فردی گفته میشود که با یکسری از اطلاعات قابل شناسایی میشود.
اطلاعاتی نظیر نام، نوع، ویژگیها و ارتباطشان با سایر موجودیتها به ما کمک میکنند تا بتوانیم ماهیت و موجودیت یک چیز را بفهمیم.
تنها زمانی یک شیء به عنوان موجودیت شناخته میشود که در فهرست موجودیتها (entity catalog) وجود داشته باشد.
کاتالوگ موجودیت یک شناسه منحصر به فرد به هر موجودیت اختصاص میدهد. اگر کلمه یا عبارتی در کاتالوگ موجود نباشد، به این معنی نیست که کلمه یا عبارت موجود نیست؛ اما معمولاً میتوانید با وجود آن در کاتالوگ متوجه شوید که آیا یک موجودیت وجود دارد یا خیر.
هنگام بررسی موجودیتها میتوان از کاتالوگ استفاده کرد. بهطور معمول موجودیت، یک شخص، مکان یا شیء است اما ایدهها و مفاهیم نیز میتوانند موجودیت داشته باشند.
منابع پیدا کردن انتیتیها
یکی از منابع شناسایی موجودیتها، ویکیپدیا است. البته وجود یا عدم وجود یک مطلب در ویکیپدیا به معنای موجودیت بودن یا نبودن قطعی آن نیست. وقتی صحبت از موجودیت به میان میآید، هر پایگاه داده یا فهرستی که حاوی اطلاعات ساختار یافته در مورد موجودیتها باشد، میتواند مبنای تعریف و شناسایی موجودیتها قرار گیرد.
چند نمونه از فهرستهای موجودیت:
- ویکیپدیا (Wikipedia)
- ویکیداده (Wikidata)
- دیبیپدیا (DBpedia)
- فریبیس (Freebase)
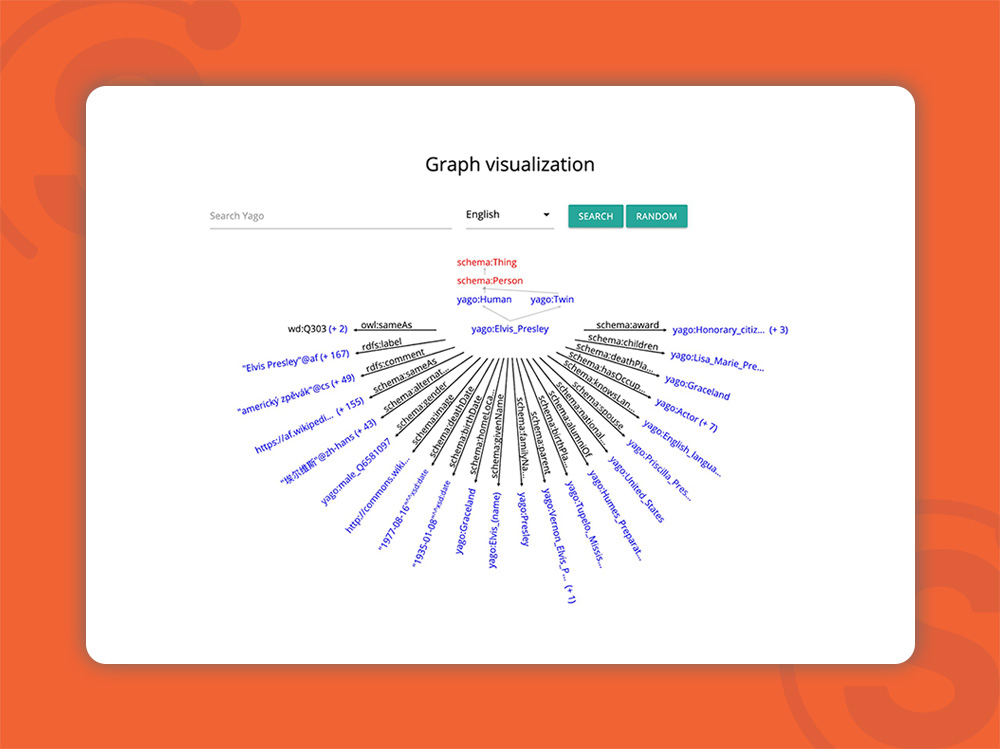
- یاگو (Yago)
کاربرد انتیتی در سئو چیست؟
موجودیتها به پر کردن شکاف بین دادههای ساختار نیافته و ساختار یافته کمک میکنند و میتوانند برای غنیسازی معنایی متون ساختار نیافته مورد استفاده قرار گیرند.
منابع متنی نیز میتوانند برای استخراج موجودیتها و ذخیرهسازی آنها در پایگاهدادهها مورد استفاده قرار گیرند. بنابراین موجودیتها پل ارتباطی بین این دو نوع داده هستند و باعث ارتباط و تعامل بین آنها میشوند.
موجودیتها باعث درک بهتر معنای متن هم برای انسان و هم برای ماشینها میشود. هرچند که فهم آنها برای انسان راحتتر است و درک آن برای ماشینها و یا موتورهای جستجو با چالشهایی همراه است.
با توجه به تغییرات مداوم دنیا و ظهور حقایق و اطلاعات جدید، پیگیری این تغییرات و بروز نگه داشتن اطلاعات موجودیتها در پایگاه دادهها نیازمند تلاش مستمر ویراستاران و مدیران محتوا است که البته کاری دشوار در مقیاس بزرگ است.
با تحلیل متون حاوی ارتباطات موجودیتها، میتوان فرآیند یافتن اطلاعات و حقایق جدید یا نیازمند بروزرسانی را آسان کرد یا حتی به کمک ماشینها آن را کاملاً بصورت خودکار درآورد.
محققان از این مسئله به عنوان «مسئله غنیسازی پایگاه داده» یاد میکنند و به همین است که دلیل لینکدهی به موجودیتها مهم است.
موجودیتها یا Entities باعث درک معنایی جستجوی کاربر و محتوای سند میشوند. و موتورهای جستجو با فهم موجودیت عبارت جستجو شده با دقت بیشتری نتایج مورد نظر کاربر را ارائه میدهد.
بنابراین Entities ابزاری مفید برای درک بهتر نیاز کاربر و محتوا و بهبود فرایند جستجو است و درک معنایی را تسهیل میکند.
در مقاله تحقیقاتی Extended Named Entity، نویسنده حدود ۱۶۰ نوع موجودیت را مورد شناسایی قرار داد که در اینجا یک عکس از فهرست انواع موجودیتهای مورد بررسی را آوردهام.

گرچه برخی از انواع موجودیتها آسانتر تعریف میشوند، اما درک مفاهیم و ایدههایی که جزء موجودیتها محسوب میشوند بسیار سخت و پیچیده است.
گوگل نمیتواند به تنهایی آنها را بهطور کامل درک کند و این ابهام را نیز صرفاً با یک فهرست موجودیتها نمیتوان برای گوگل برطرف کرد.
درک موجودیتهای پیچیدهای مثل مفاهیم و ایدهها توسط ماشینها، مستلزم ایجاد محتوای گسترده و بلند مدت است.
چرا انتیتی مهم است؟
گوگل با معرفی قابلیتهای یادگیری ماشینی و به کمک استفاده از پایگاههای اطلاعاتی نیمه ساختاریافته و ساختاریافته، توانست معنای کلمات کلیدی را درک کند.
اکنون و بعد از گذشت نزدیک به ۱۱ سال، گوگل دیگر صرفاً به دنبال نتایج ساده بر اساس کلمات کلیدی نیست و حال میخواهد موجودیتها و ارتباطات میان موجودیتهای مختلف را درک کند تا نتایج بهتری ارائه دهد.
من فکر میکنم در دو سال آینده سئوی انتیتی، مبنای انجام استراتژیهای سئو خواهد بود. در واقع در آینده موتورهای جستجو مبنای رتبهبندی و حرکت خود را بر اساس معنا قرار میدهند.
نمونههایی از انتیتی و موجودیتها
حال شاید فکر کنید آیا تا به حال با انتیتیها برخورد داشتهاید یا نه؟
حتماً تاکنون چندین نمونه از انتیتیهای SERP که رایجترین آنها نام شهرها، کشورها، افراد مشهور، برندها است را دیدهاید.
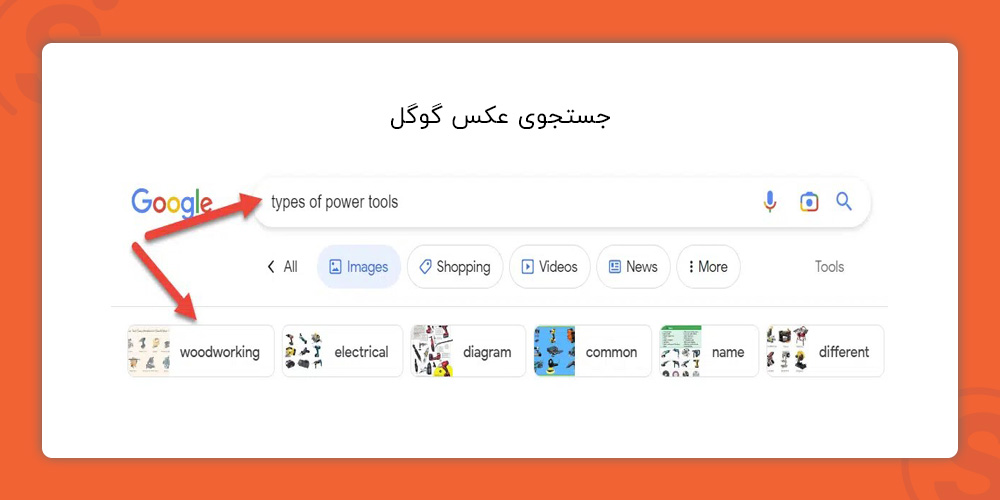
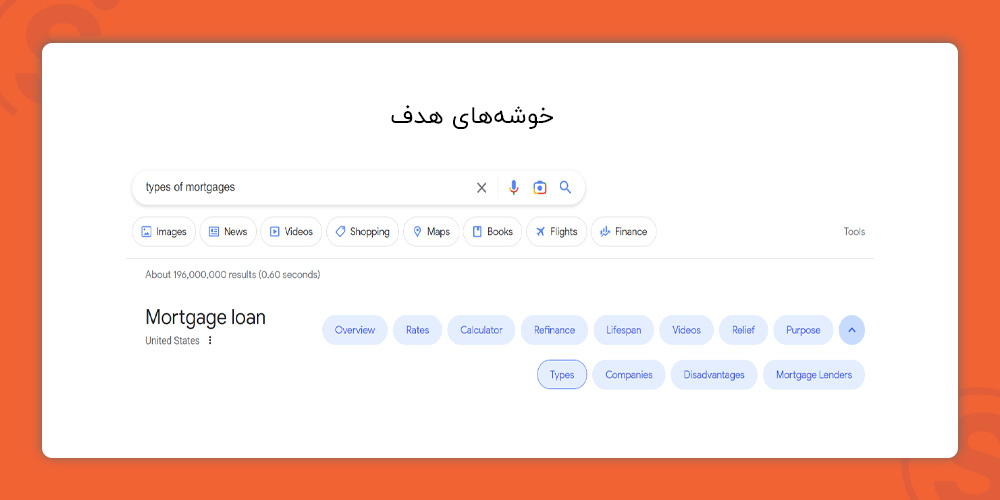
از بهترین نمونههای موجودیت در صفحات نتایج جستجو، میتوان به خوشهبندی بر اساس هدف و قصد کاربر از جستجو اشاره کرد.
هرچه یک موضوع برای موتور جستجو بیشتر قابل درک باشد، این ویژگیهای جستجو بیشتر ظاهر میشوند. همچنین به کمک یک کمپین سئو میتوان با تمرکز بر موجودیتها، چهره صفحات نتایج جستجو را نیز تغییر داد.
ورودیهای ویکیپدیا نمونه دیگری از موجودیتها هستند. ویکیپدیا نمونهای عالی از اطلاعات مرتبط با موجودیتها ارائه میکند.
همانطور که در سمت چپ عکس زیر میبینید از بالا تا پایین، موجودیت شامل انواع ویژگیهای مرتبط با «ماهی» از آناتومی آن گرفته تا اهمیتش برای انسان است.
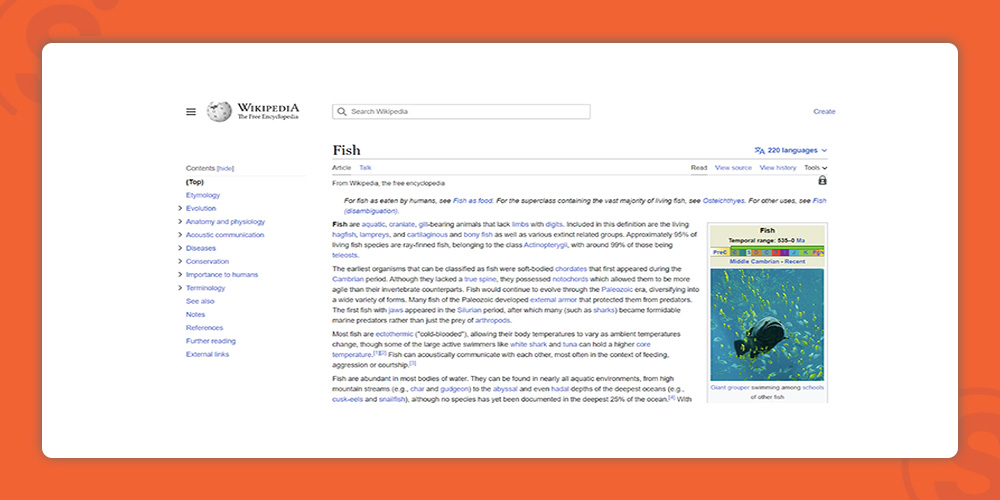
البته این را هم اضافه کنم هر چند که ویکیپدیا حاوی اطلاعات زیادی در مورد یک موضوع است، اما به هیچ وجه جامع نیست.
۵ نکته در مورد Entities که باید بدانید
من در ادامه به ۵ نکته مهم که باید در مورد Entities بدانید و از آنها بهترین استفاده را در سئو ببرید، اشاره میکنم.
۱- روی مفهوم محتوا تمرکز کنید
گوگل این روزها بیشتر به دنبال درک مفهوم محتوای شما هست و تکرار کلمات کلیدی مشابه به تنهایی رضایتش را جلب نمیکند.
از آنجایی که انتیتی به ماهیت و موجودیت اشیاء، افراد، مکانها و مفاهیم انتزاعی اشاره دارد، شما باید به جای تمرکزِ صرف بر روی کلمات کلیدی و کیوردها، روی مفهوم محتوا تمرکز کنید. به این معنی که از واژههای با مفاهیم مرتبط با موضوع محتوا بیشتر استفاده کنید.
مثلا اگر موضوع محتوای شما درباره «جنگل آمازون» است، از کلمات و انتیتیهایی مثل «درخت»، «جنگل»، «طبیعت»، «محیط زیست»، «گونههای جانوری»، «آمریکای جنوبی»، «جنگل بارانی» و… در جایجای متن محتوا استفاده کنید.
به این ترتیب خزندههای گوگل و سیستم جستجوی گوگل گراف به ارتباط مفهومی و معنایی بین این کلمات با موضوع محتوای شما پی میبرند و آن را برای کیوردهای مرتبط با جنگل آمازون ایندکس میکنند.
درنتیجه، وقتی یک کاربر در گوگل عبارت کلیدی «سایت آمازون» را سرچ میکند، محتوای سایت شما به نمایش درنمیآید. ولی وقتی عبارت جستجو «جنگل بارانی»، «بزرگترین جنگل آمریکای جنوبی» و انتیتیهای دیگر باشد، محتوای شما در میان نتایج به نمایش درمیآید.
این کار همچنین به قرار گیری محتوای شما در دستهبندیهای مختلف جستجوی پیشرفته گوگل هم کمک میکند. مثلا در تصویر زیر میبینید که برای نتایج سرچ عبارت «جنگل آمازون» تصاویری از انتیتیهای مختلف مثل طبیعت، درختان، مار، عکس و… به نمایش درآمده است.
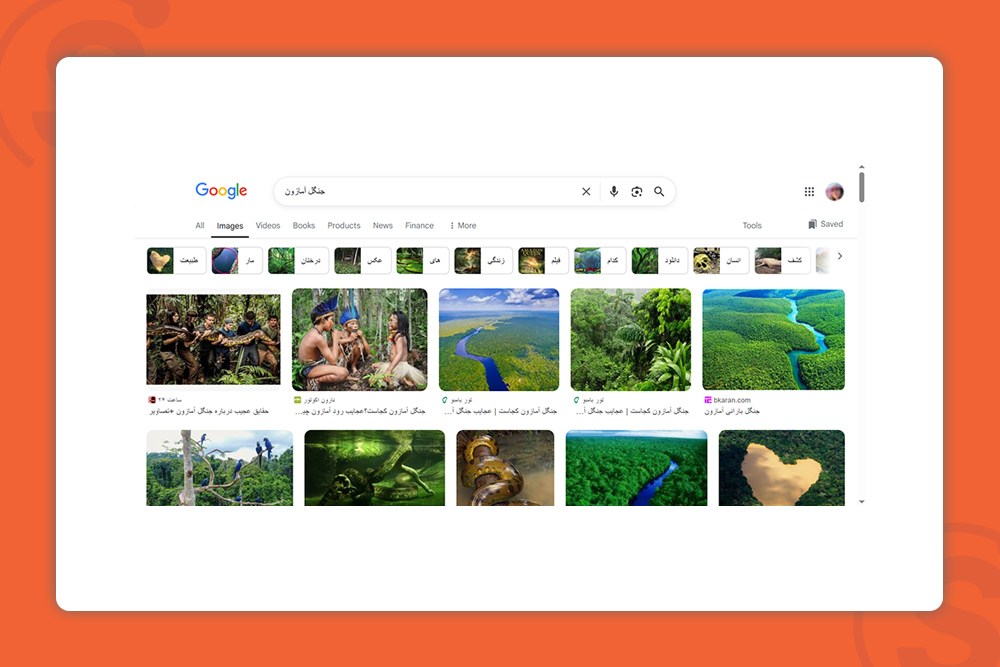
پس به جای اینکه فقط روی کلمات کلیدی اصلی و فرعی و چگالی آنها برای سئو تمرکز کنید، از Entities و کلمات مرتبط به لحاظ مفهوم، معنا و دستهبندی مفهومی هم استفاه کنید.
انتیتیها را در قسمتهای مختلف متن محتوا مثل عنوان، زیرعنوان، پاراگرافهای اول، بدنه متن و… به کار ببرید.
۲- خوانا و روان بنویسید
وقتی میخواهید محتوایتان برای مخاطب و گوگل قابل درک و فهم باشد، باید آن را با زبانی خوانا و روان بنویسید. به عبارتی، باید متن خود را به زبان طبیعی و کاربرد پسند یا NLP-friendly بنویسید.
برای اینکه متن محتوای شما خوانا و روان باشد و برای کاربر و گوگل قابل فهم باشد، از این نکات استفاده کنید:
- از کلمات و عبارات ساده، قابل فهم و شفاف برای رساندن منظور خود استفاده کنید.
- از کلمات یا عبارات پیچیده و قلمبه سلبمه استفاده نکنید.
- در کنار کلمات دشوار و پیچیده از مترادفها یا کلمات معادل ساده هم استفاده کنید.
- مثالهای بیشتری بزنید. مثالها نمونه خوبی از عبارتهای ساده و روان برای توضیح مفاهیم پیچیده هستند.
۳- انتیتیهای مرتبط با موضوع را بیابید
همانطوری که شما در ابتدای تولید محتوا و بر اساس ایده یا موضوعی که دارید، به تحقیق کلمات کلیدی یا کیورد ریسرچ میپردازید تا ترندترین کلمات کلیدی در جستجوهای کاربران را پیدا کنید، برای یافتن انتیتیها هم باید تحقیق کنید.
برای تحقیق و یافتن انتیتیهای مرتبط با موضوع و مفهوم محتوای خود میتوانید از گوگل یا ابزارهای سئو استفاده کنید. چند مورد از این ابزارها عبارتند از:
- SEMrush Entity Report
- Topically.io
- TextRazor
این ابزارها به شما در جستجوی Entityهای مرتبط با یک موضوع کمک میکنند. کارایی اصلی این ابزارها در تحقیق و جستجوی انتیتیهای به زبان انگلیسی یا غیرفارسی است و معمولا در یافتن انتیتیهای فارسی کمک زیادی نمیکنند.
شما میتوانید در کنار این ابزارها از هوش مصنوعی هم برای یافتن کلمات مرتبط از نظر معنایی و مفهومی کمک بگیرید.
مثلا در تصویر زیر میبینید که از ChatGPT برای پیدا کردن انتیتیهای مرتبط با «جنگل آمازون» استفاده کردم و نتایج خوبی به دست آوردم:
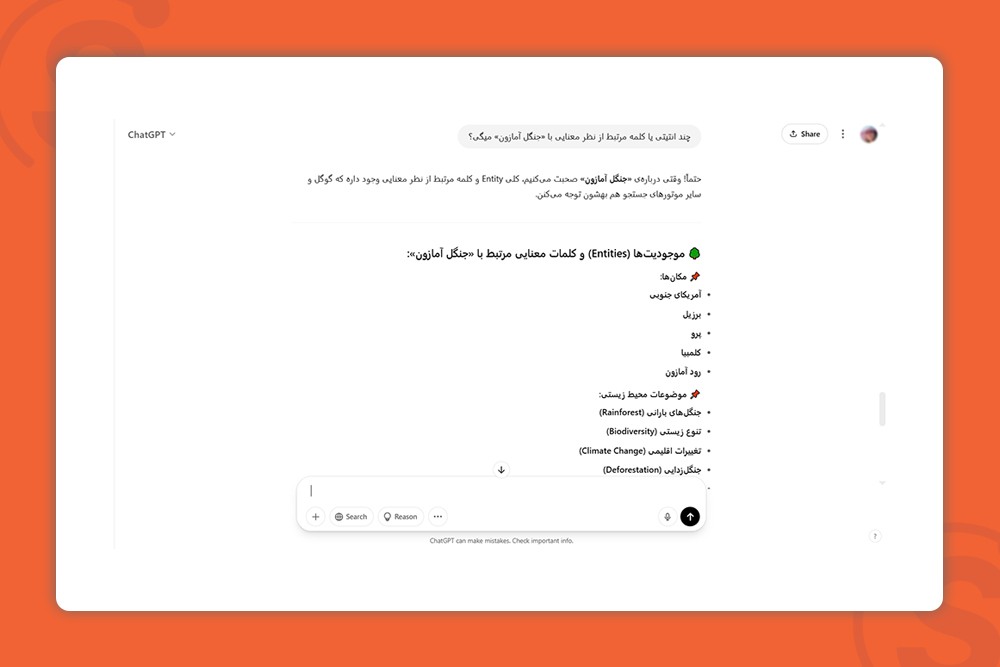
۴- از کدهای اسکیما استفاده کنید
گوگل و سایر موتورهای جستجو درکی از زبان انسان ندارد و متن محتوا را مانند ما نمیخوانند، بلکه با کدها و دادههای درج شده در بخش ادیتور محتوا یا بکاند سایت، محتوا را میخواند.
زبان گوگل کدهای ساختاریافته یا کدهای جاوا، HTML و… است. اگر میخواهید خزندههای گوگل متوجه انتیتیها بشوند و مفاهیم آنها را درک کنند، با زبان خودشان با آنها حرف بزنید.
کدهای اسکیما مارک آپ Schema یا دادههای ساختار یافته (استراکچر دیتا Structured data) یکی از روشهای ارتباط با خزندههای گوگل به زبان خودشان است.
این نشانهگذاریها کمک میکند تا خزندهها را متوجه وجود انتیتیهای محتوا کنیم. در دوره اسکیما میتوانید با مفهوم استراکچر دیتا و نحوه استفاده از آن در سئو آشنا شوید.
با این کدهای اسکیما میتوانید انواع موجودیتها یا ماهیتهایی که در متن به آنها اشاره کردهاید را به خزندههای گوگل معرفی کنید. کاربردیترین کد اسکمیا برای شناساندن انتیتی به گوگل، کد @type است.
مثلا در کد زیر، من انتیتی «جنگل بارانی آمازون» یا همان «Amazon Rainforest» را به عنوان دسته یا تایپ «مکان / place» معرفی میکنم:

به این ترتیب، گوگل متوجه میشود که محتوای سایت من را در دسته «جنگلهای بارانی» در نمایش پیشرفته صفحهی نتایج به نمایش دربیاورد.
سایر کدهای کاربردی اسکیما برای شناساندن انتیتیهای مورد استفاده در محتوا به گوگل عبارتند از:
- @organization
- @place
- @person
- @product
- @about
- @mention
۵- هم پوشانی معنایی را رعایت کنید
هم پوشانی معنایی Semantic Clustering به استفاده از کلمات یا عبارات مرتبط از نظر معنایی با یک کیورد گفته میشود. مثلا اگر کیورد اصلی شما «طبیعتگردی» است باید از کلمات مرتبط از نظر معنایی مثل «طبیعت»، «گردشگری»، «تور» و… به همراه این کیورد در متن محتوا استفاده کنید تا آن را از لحاظ معنایی همپوشانی دهند.
همین کار را با انتیتی هم باید انجام دهید. یعنی اگر برای محتوای خود با کیورد «جنگل آمازون» از Entityهایی مثل جنگل، آمریکای جنوبی، جنگل بارانی، برزیل و… استفاده میکنید، این انتیتیها را با عبارات مرتبط از نظر معنایی همپوشانی دهید.
یعنی مثلا برای انتیتی «جنگل بارانی» از کلماتی مثل «جنگل انبوه»، «باراش باران»، «درختان سبز پهن برگ»، «جنگل استوایی» و… در لابهلای متن خود استفاده کنید.
نکات دیگر کاربرد انتیتی ها
علاوه بر ۵ نکته مهم و کاربردی که برای استفاده بهینه از انتیتیها در سئو نام بردم، بهتر است نکات زیر را هم در تولید محتوا و سئو رعایت کنید:
- انتیتیها را در متن و در جاهای مختلف مثل هدر، زیر هدر، پاراگراف اول محتوا و… تکرار کنید.
- در تکرار انتیتیهای زیاده روی نکنید و به اندازه منطقی آنها را به کار ببرید.
- بین انتیتیهای مختلفی که در محتوا استفاده میکنید، ارتباط ایجاد کنید.
- از سایتهای رقیب برای یافتن Entities ارزشمند و مرتبط کمک بگیرید.
- به سایتهای مرجع و معتبر انتیتی مثل ویکی پدیا لینک بدهید (تا به گوگل در تشخیص انتیتی کمک کنید.)
- از ابزارهای تحلیل Entityها برای یافتن بهترین ماهیتها یا تشخیص ماهیتهای ضعیف استفاده کنید.
چند نمونه از استفاده انتیتی ها توسط گوگل
برای اینکه با انتیتیها به طور ملموس و شفاف آشنا شوید، چند نمونه از استفاده آنها توسط گوگل را به شما نشان میدهم.
Entities در سرچ تصویری گوگل
در صفحه نتایج سرپ گوگل و در تب تصاویر، برای هر جستجو، تصاویر مربوط به عبارت جستجو به نمایش درمیآید. مثلا در تصویر زیر میبینید که برای جستجوی کلمه «درخت» چندین دسته از تصاویر را به صف کرده است.
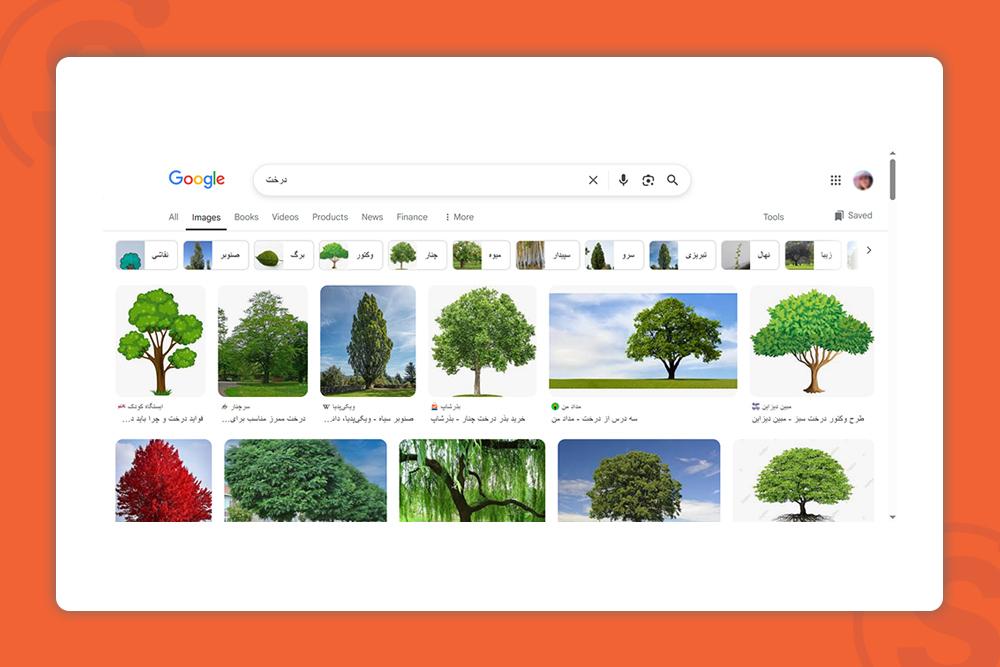
هر کدام از این تصاویر مربوط به محتوایی از سایتهای مختلف است. گوگل بر اساس متن جایگزین تصویر یا تگ Alt یا (Alt text)، این تصاویر را در صفحه نتایج به نمایش درمیآورد.
همانطور که مشاهده میکنید، گوگل بر اساس یک دستهبندی از انتیتیهای مختلف که به کلمه درخت مرتبط هستند، این تصاویر را به نمایش درآورده است. این انتیتیها عبارتند از: صنوبر، برگ، میوه، چنار، نهال، زیبا و… .
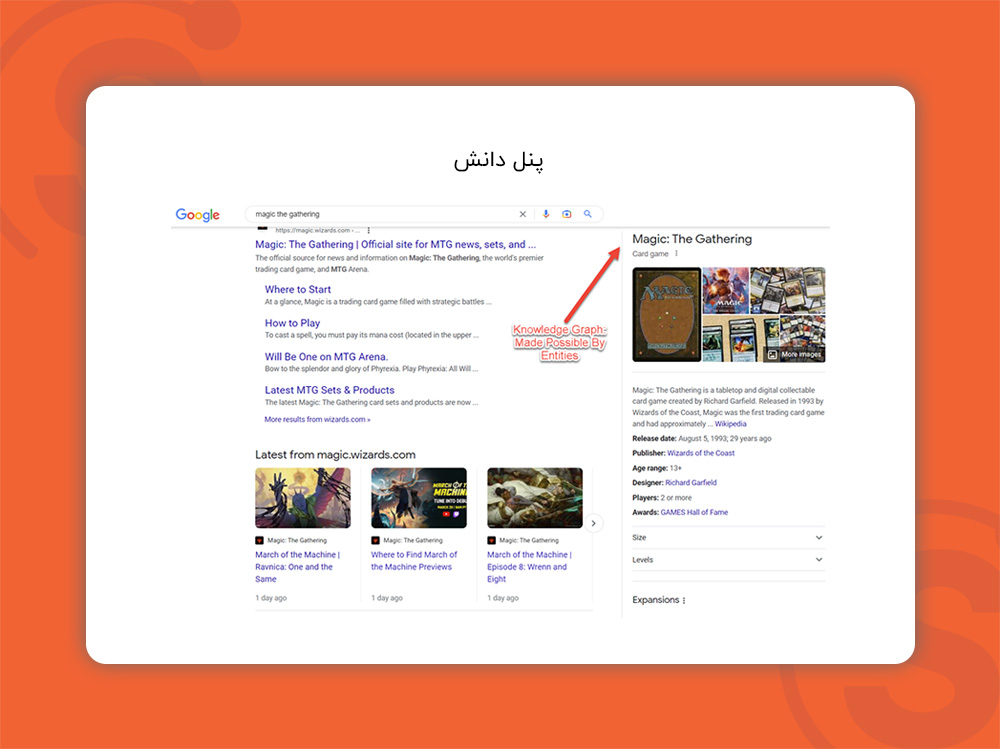
پنل دانش گوگل (Knowledge Panel)
یکی دیگر از بخشهای سرپ گوگل که انتیتیها را به نمایش درمیآورد، پنل دانش گوگل knowledge Panel است. این بخش از صفحه نتایج گوگل که به صورت یک کادر اطلاعاتی در گوشهای از سرپ به نمایش درمیآید، اطلاعات کامل و جامعی را در مورد یک چیز یا شخص نشان میدهد.
مثلا در تصویر زیر پنل دانش مربوط به پروفسور سمیعی را مشاهده میکنید:
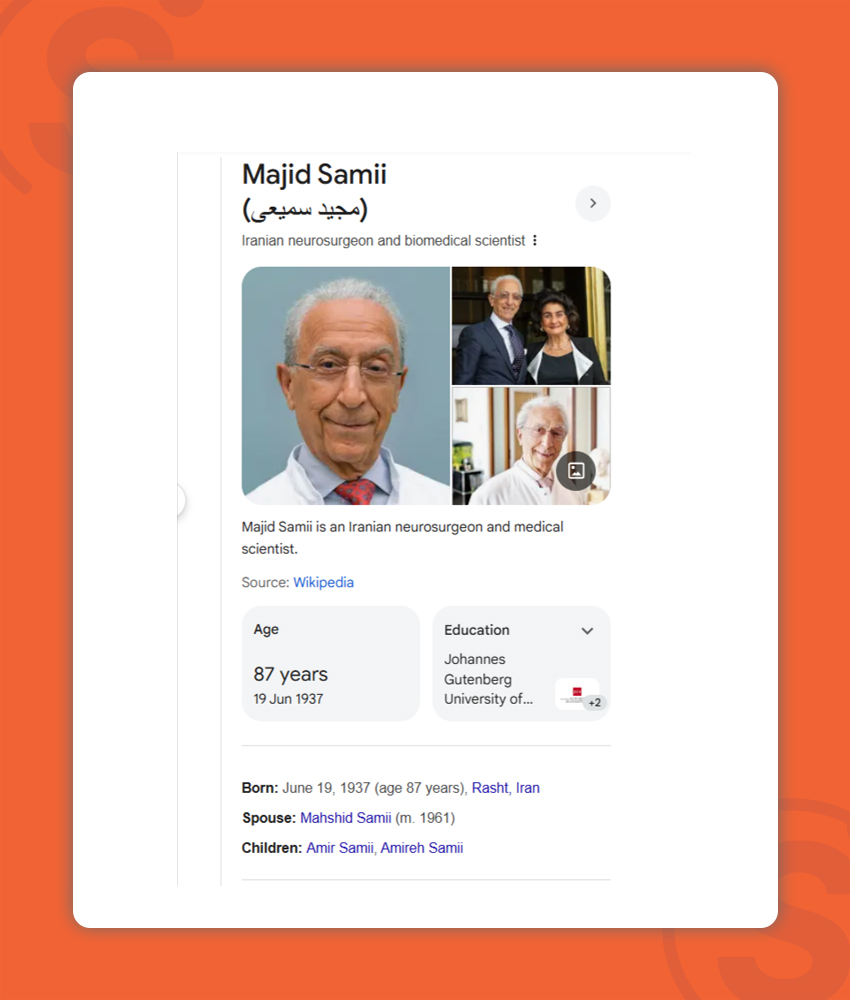
این پنل توسط گوگل و بر اساس انتیتیهایی مثل فردیت، جنسیت، شغل، سن و… طراحی و نمایش داده میشود. پنل دانش گوگل با Knowledge graph مرتبط است.
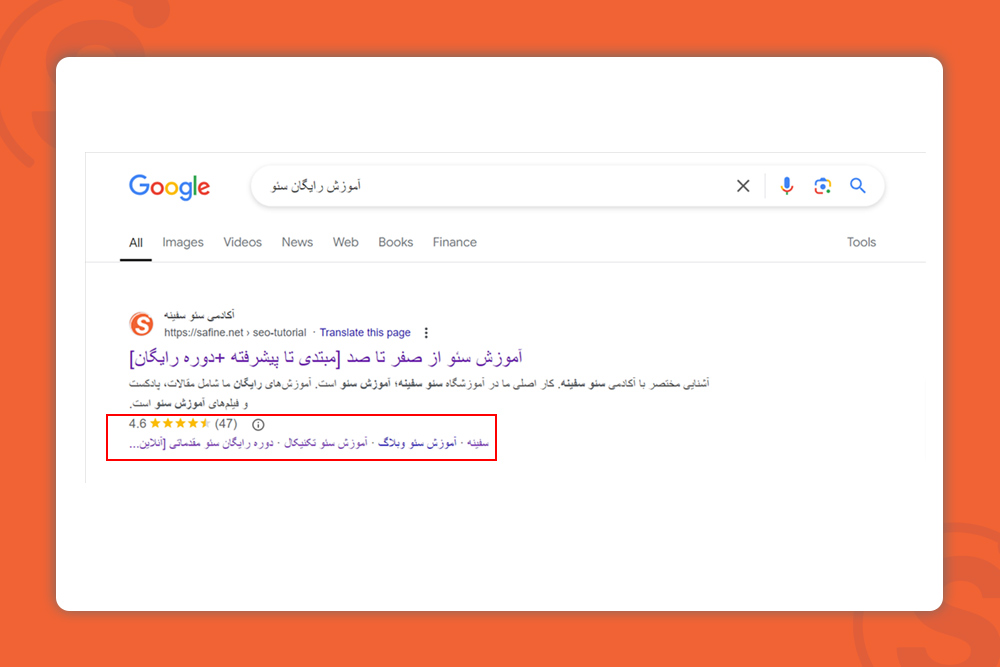
ریچ اسنیپت Rich Snippet
ریچ اسنیپ Rich Snippet بخشی از اطلاعات مربوط به لینک سایت شماست که در کنار لینک به نمایش درمیآید. مثل ستاره، قیمت، آراء ثبت شده، FAQها و غیره.
ریچ اسنیپت بر اساس انتیتیهای به کار رفته در محتوای سایت شما و با استفاده از دادههای ساختار یافته یا کدهای اسکیما فعال میشود.
چند نمونه دیگر از نمایش نتایج در گوگل بر اساس انتیتیها عبارتند از:
- Image Pack/video Pack
- فیچر featured snippet
- Local pack/ Map pack
اهمیت انتیتی یا ماهیت در سئو
گوگل در سالهای اخیر با بهروزرسانی و معرفی الگوریتمهای جدید مثل الگوریتم مرغ مگس خوار یا Hummingbird و الگوریتم برت BERT و همچنین ارائه گراف دانشknowledge graph، معیارهای خود برای رتبهبندی را عوض کرده است.
گراف دانش یک دیتابیس شِبه-ساختاریافته و دربرگیرنده انتیتیها است که به گوگل در رصد و اسکن دقیق وبسایت شما و یافتن انتیتیها کمک زیادی میکند. ویکیپدیا، ویکی دیتا، Freebase و Yago چند نمونه از گرافهای موجود هستند. درواقع، خرید Freebase توسط گوگل در سال ۲۰۱۰ استارت کار راهاندازی سیستم جستجوی انتیتی بود.
و امروزه، برعکس سئوی قدیم که فقط به کیوردهای محتوا متکی بود، در سئوی جدید، انتیتیها هم در الویتهای خزندههای گوگل برای ایندکس و رتبهبندی محتوا در رنکهای بالای SERP قرار گرفتهاند.
بنابراین اگر به درستی از ماهیتها یا موجودیتها در محتوای سایت خود استفاده کنید، به خزندههای گوگل در درک مفهوم آن، ایندکس آن برای انتیتیهای مرتبط، رتبهبندی در رنکهای بالا و افزایش اعتبار سایت شما کمک بسیار زیادی میکنید.
آیا انتیتی همان کیورد فرعی است؟
با اینکه انتیتی از نظر مفهومی با کیوردها شبیه است ولی کیورد فرعی نیست. کیوردهای فرعی از نظر املایی و نگارشی مشابه کیوردهای اصلی هستند. مثلا عبارات «خرید لپتاپ»، «لپتات جدید»، «لپتاپ ایسوس» و «ارزانترین لپتاپ» چند نمونه از کیوردهای فرعی برای کیورد اصلی «لپتاپ» هستند.
اما انتیتیها معمولا به شکل «CPU»، «لنوو»، «ایسوس»، «لپتاپ گیمینگ»، «طراحی گرافیک» و غیره هستند. مشاهده میکنید که در انتیتیها لزوما از کیورد اصلی استفاده نمیشود.
تاریخچه گوگل در زمینه موجودیتها
گوگل در سال ۲۰۱۰ با خرید سایت Freebase، اولین گام مهم در زمینهی ایجاد سیستم فعلی جستجوی موجودیتها را برداشت.
با خرید Freebase، گوگل به یک پایگاه داده بزرگ ساختاریافته در مورد موجودیتها دسترسی پیدا کرد و این نقطه شروعی شد برای توسعه قابلیتهای موجودیت محور موتور جستجوی گوگل.
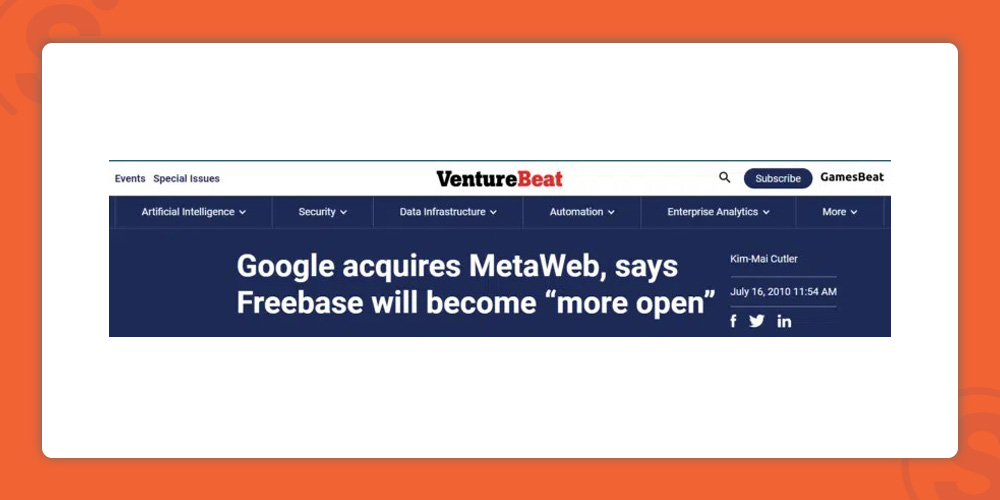
البته گوگل بعد از سرمایهگذاری بر Freebase متوجه شد Wikidata گزینهی بهتری برای پایگاه داده موجودیتها میتواند باشد و سعی کرد با هر مشکل و دشواری که وجود دارد این دو سایت را با هم ادغام کند.
از دلایل این تغییر میتوان به آن اشاره کرد که پایگاه داده Freebase، بر پایه اشیاء، واقعیتها و ویژگیها بنا شده است. و هر شیء در Freebase دارای یک شناسه ثابت به نام mid (مخفف Machine ID) است.
اما در Wikidata دادهها بر مبنای مفاهیم آیتم و توضیح طراحی شده است. هر آیتم نمایانگر یک موجودیت است و دارای یک شناسه ثابت به نام qid میباشد.
همچنین ممکن است هر آیتم دارای برچسبها، شرح و توضیحات و نامهای مترادف به زبانهای مختلف باشد. علاوه بر این آیتمها حاوی توضیحات و لینکهای بیشتری به صفحات مرتبط با آن موجودیت در سایر پروژههای ویکیمدیا از جمله ویکیپدیا هستند.
همچنین بیانیههای Wikidata به دنبال کدگذاری حقایق و واقعیتها نیستند، بلکه ادعاهایی از منابع مختلف را نمایش میدهند که ممکن است با هم در تناقض باشند.
پروژه Schema
گوگل به کمک شرکتهای بینگ و یاهو، پروژه Schema.org را برای افزایش دانش موجودیت خود در دادههای ساختار نیافته مانند متنهای وبلاگها راهاندازی کرد.
به کمک دستورالعملهای موجود در اسکیما، گوگل محتوای صفحات را بهتر میتواند درک کند.
به گفتهی گوگل وبمسترها میتوانند با ارائه دادههای ساختاریافته در صفحه، به گوگل در درک معنای محتوای صفحه کمک کنند.
دادههای ساختاریافته یک قالب استاندارد شده برای ارائه اطلاعات در مورد یک صفحه و طبقهبندی محتوای صفحه است.
برای مثال اگر یک وبلاگ آموزش آشپزی دارید میتوانید در صفحهای که دستور پخت غذا را یادداشت میکنید بصورت ساختاریافته اطلاعاتی مانند مواد لازم، زمان و دمای پخت، میزان کالری و… نیز وارد کنید تا گوگل بهتر بتواند معنای صفحه را درک کند.
همچنین گوگل میگوید برای اینکه یک شیء به صورت پیشرفته به نمایش دربیاید باید تمامی ویژگیهای مورد نیاز آن درج شود.
بهطور کلی هرچه اطلاعاتی که شما از آن شیء یا مفهوم بصورت توصیفی از آن درج میکنید بیشتر باشد، احتمال اینکه اطلاعات شما با نمایش پیشرفته در نتایج جستجو ظاهر شود بیشتر میشود.
دربارهی اسکیما هم باید بگویم یک ابزار باورنکردنی برای سئوکارانی است که به دنبال شفافسازی محتوای صفحه برای موتورهای جستجو هستند.
گل نهایی گوگل نیز با آخرین اطلاعیه منتشر شده با عنوان «بهبود جستجو برای ۲۰ سال آینده» زده شد.
ایدهی اصلی پشت این اطلاعیه، ارتباط و کیفیت سند است. اولین روش گوگل برای تعیین محتوای یک صفحه تمرکز بر کلمات کلیدی بود. سپس گوگل لایههای موضوعی را به جستجو اضافه کرد. این لایه به کمک نمودارهای دانش و پالایش و ساختاردهی سیستماتیک دادهها در سراسر وب امکان پذیر شد که به کمک آن، سیستم فعلی جستجو امکانپذیر شد.
گوگل در کمتر از ۱۰ سال از ۵۷۰ میلیون موجودیت به ۸ میلیارد موجودیت و از ۱۸ میلیارد دلیل به ۸۰۰ میلیارد دلیل دست یافته است. با رشد و افزایش این اعداد، جستجوی موجودیت نیز بهبود مییابد.
مزیت برتری مدل موجودیت نسبت به مدلهای جستجوی قبلی چیست؟
مدلهای قدیمی بازیابی اطلاعات (IR) که مبتنی بر کلمات کلیدی هستند دارای محدودیت ذاتی در عدم بازیابی اسناد هستند که هیچ انطباق درستی با با عبارت جستجو شده ندارند.
مدلهای قدیمی جستجو تنها میتوانند اسنادی را بازیابی کنند که شامل کلمات کلیدی مشخص شده در عبارت جستجو هستند.
به عنوان مثال اگر با استفاده از ctrl+f بخواهید کلمهای را در یک صفحه پیدا کنید، از همان اصول مدلهای سنتی بازیابی اطلاعات استفاده میکنید.
حجم بسیار زیادی از داده هر روز در بستر وب منتشر میشود. درک معنای همهی کلمات، پاراگرافها، مقالات و محتویات وبسایتها برای گوگل امکانپذیر نیست.
برای این منظور موجودیتها ساختاری برای گوگل فراهم میکنند که بتواند با بهرهگیری از آن، بار محاسباتی را کاهش دهد و در عین حال درک بهتری از موجودیتها داشته باشد.
موجودیتها به گوگل اجازه میدهند به جای تجزیه و تحلیل کل متن، تنها روی بخشهای کلیدی و ساختاریافتهای از اطلاعات متمرکز شود که درک معنایی آنها اهمیت دارد.
در بخشی از کتاب جستجوی موجودیتگرا آمده است: «روشهای بازیابی اطلاعات مبتنی بر موجودیت، با هدف غلبه بر چنین چالشهایی در بازیابی متن، از ساختارهایی مانند واژگان کنترل شده (دیکشنری و فرهنگ جامع)، هستیشناسی و موجودیتهای استخراج شده از مخازن دانش بهره میگیرند.
این ساختارها باعث میشوند درخواستها و مدارک از لحاظ موجودیت غنیتر شده و در یک فضای معنایی و موجودیت سطح بالاتر قرار گیرند. در نتیجه، تطابق بهتری بین درخواستها و مدارک برقرار میشود و بازیابی دقیقتر و مرتبطتری حاصل میگردد.»
دیدگاه کریستیان بالوگ در مورد انتیتی
کریستیان بالوگ، که کتاب جستجوی موجودیتگرا را نوشته است، سه راه حل ممکن برای مدل سنتی بازیابی اطلاعات را بصورت زیر تعریف میکند که البته درک آن بسیار سنگین است:
- راهکار مبتنی بر توسعه: در آن از موجودیتها به عنوان منبعی برای توسعه و غنیسازی درخواست کاربر با اصطلاحات مختلف استفاده میشود.
- راهکار مبتنی بر طراحی: در آن ارتباط بین درخواست کاربران و سند (مثلا صفه وب) از طریق طراحی آنها بر روی فضای نهفتهای از موجودیتها درک میشود.
- راهکار مبتنی بر موجودیت: در آن بازنمایی معنای درستی از درخواستهای کاربران و اسناد در فضای موجودیتها به دست میآید تا بازنمایی مبتنی بر اصطلاح را تقویت کند.
هدف این سه رویکرد بدست آوردن نمایشی غنیتر از اطلاعات مورد نیاز کاربر با شناسایی موجودیتهایی است که به شدت با کوئری کاربر مرتبط هستند.
۶ الگوریتم بالوگ در خصوص انتیتیها
بالوگ سپس شش الگوریتم را معرفی میکند که با روشهای مبتنی بر طراحی برای نگاشت موجودیتها مرتبط هستند.
روشهای طراحی مربوط به تبدیل موجودیتها به فضای سهبعدی و اندازهگیری بردارها با استفاده از هندسه است. این کار به نوعی یک تصویرسازی است.
- تحلیل معنایی صریح (ESA): در این الگوریتم، معنای یک واژه با استفاده از یک بردار توصیف میشود که این بردار، قدرت ارتباط آن واژه را با موجودیتها استخراج شده از ویکیپدیا را ذخیره میکند. به عبارت دیگر بردار نشان میدهد که آن واژه تا چه حد با هر یک از موجودیتها ویکیپدیا مرتبط است. این کار باعث میشود معنای واژه به صورت کمی و بر اساس ارتباط آن با موجودیتهای دیگر توصیف شود.
- مدل فضای پنهان موجودیت (LES): این الگوریتم مبتنی بر یک چارچوب احتمالی مولد است. این مدل امتیاز بازیابی سند را بر اساس ترکیب خطی از امتیاز مرتبط بودن آن سند با موجودیتهای نهفته و امتیاز مرتبط بودن آن با خود عبارت جستجو شده محاسبه میکند.
- EsdRank: یک الگوریتم برای رتبهبندی اسناد است که از ترکیبی از ویژگیهای جستار-موجودیت و موجودیت-سند استفاده میکند. این ویژگیها به ترتیب موجودیتها تصویرسازی جستار و تصویرسازی سند را در مدل LES منعکس میکنند. EsdRank از یک چارچوب یادگیری تشخیصی استفاده میکند که اجازه میدهد سیگنالهای اضافی مانند محبوبیت موجودیت یا کیفیت سند به راحتی در الگوریتم لحاظ شوند.
- رتبهبندی معنایی صریح (ESR): این مدل با هدف انجام تطابق متعادل بین درخواست کاربر و اسناد در فضای موجودیتها، از اطلاعات رابطهای موجود در گرافهای دانش استفاده میکند. به عبارت دیگر، این الگوریتم با بهرهگیری از اطلاعات گراف دانش در مورد روابط بین موجودیتها، قادر است تطابقها و ارتباطات ضمنی و معنایی بین عبارات جستجو شده توسط کاربر و اسناد را در سطح موجودیتها شناسایی کند. به این ترتیب، تطابقهای معنایی فراتر از سطح واژگان حاصل میشود.
- چارچوب دوطرفهی واژه-موجودیت: این الگوریتم تعاملات بین دو نوع نمایش متن یعنی مبتنی بر واژه و مبتنی بر موجودیت را در نظر میگیرد. این چارچوب با در نظر گرفتن چهار نوع تطابق بین جستار و سند شامل تطابق واژگان جستار با واژگان سند، تطابق موجودیتهای جستار با واژگان سند، تطابق واژگان جستار با موجودیتهای سند و تطابق موجودیتهای جستار با موجودیتهای سند، سعی در لحاظ کردن تطابقها در سطوح مختلف واژگانی و معنایی دارد.
- مدل رتبهبندی مبتنی بر توجه: این مدل پیچیدهترین مدل در بین سایر مدلهای مبتنی بر موجودیت برای رتبهبندی اسناد است و توضیح کامل این الگوریتم نیازمند ورود به جزئیات فنی و پیچیده است.
بالوگ در کتاب خود میگوید: «مجموعاً چهار ویژگی، مبتنی بر توجه طراحی شده است که برای موجودیت هر عبارت جستجو شده استخراج میشوند. ویژگیهای ابهام موجودیت قرار است خطر مرتبط با حاشیهنویسی موجودیت را مشخص کنند. این ویژگیها عبارتند از:
- آنتروپی احتمال ارتباط شکل سطحی به موجودیتهای مختلف (مثلاً در ویکیپدیا)
- اینکه آیا موجودیت تشریح شده معمولترین معنا برای فرم سطحی است (یعنی بیشترین امتیاز مشترک را دارد)
- تفاوت در امتیازات مشترک بین محتملترین و دومین گزینه محتمل برای فرم سطحی داده شده
- نزدیکی که به عنوان شباهت کسینوسی بین موجودیت جستار و خود جستار در یک فضای جانمایی شده تعریف میشود
بهطور خاص، یک مدل جانمایی مشترک واژه-موجودیت با استفاده از الگوریتم skip-gram روی یک مجموعه داده آموزش داده میشود.
در این مجموعه داده آموزشی، موجودیتهای ارجاع شده با شناسههای موجودیت مربوط به خودشان جایگزین شدهاند. سپس بردار جانمایی مربوط به جستار، به عنوان مرکز ثقل (میانگین) بردارهای جانمایی واژگان تشکیل دهنده عبارت جستجو شده در نظر گرفته میشود.»
در حال حاضر آشنایی سطحی با این شش الگوریتم موجودیت محور مهم است و خیلی نیاز نیست وارد جزئیات ریز آن شد.
اما یادتان باشد برای استفاده از موجودیتها در بازیابی اطلاعات دو رویکرد اصلی وجود دارد و آنها طراحی و نگاشت اسناد به یک لایه یا فضای نهان از موجودیتها و حاشیهنویسی و برچسبگذاری صریح موجودیتها در درون متن اسناد است.
سه مدل ساختار داده
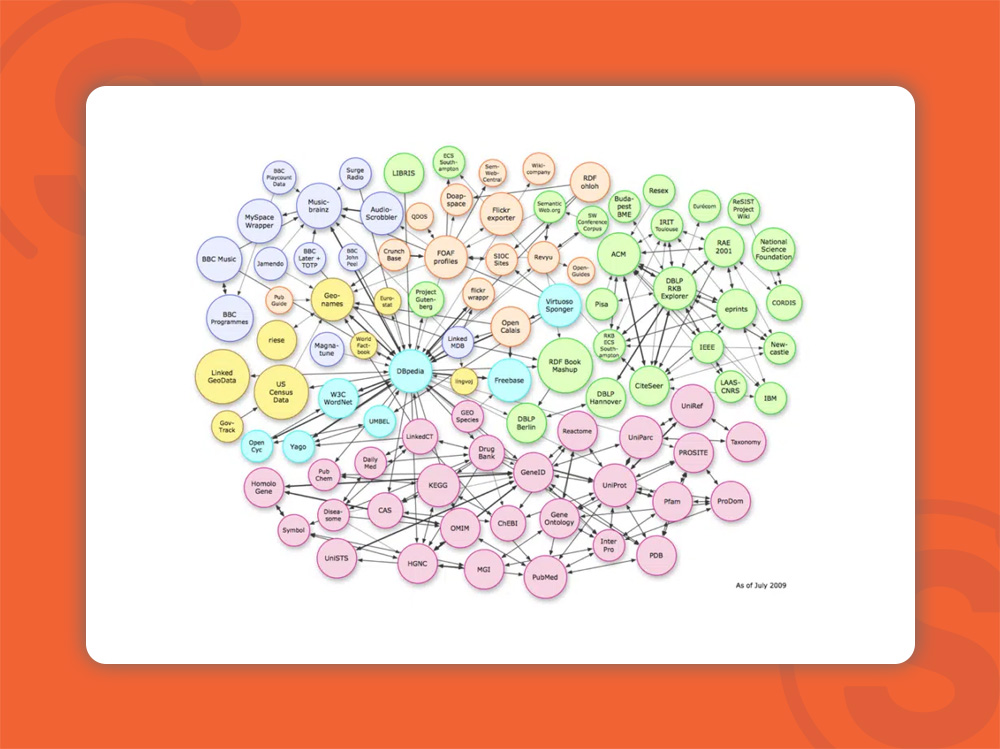
تصویر بالا روابط پیچیدهی بین موجودیتها را در فضای برداری را نشان میدهد. اگرچه این عکس ارتباطات نموداری بین دانشها را نشان میدهد اما برای درک بهتر ماهیت موجودیتها، شناخت سه نوع ساختار دادهای که الگوریتمها از آنها استفاده میکنند، ضروری است:
هنگام توصیف موجودیتهای ساختار نیافته، اگر برای توصیف از موجودیتهای دیگر کمک گرفته شده؛ باید این موجودیتها شناسایی و ابهام زدایی شوند. و مانند شکل بالا پیکان خط نموداری (هایپرلینکها) از هر موجودیت به موجودیت دیگری که در توضیحات آورده شده ذکر شود.
در یک محیط نیمه ساختاریافته (به عنوان مثال ویکی پدیا)، ممکن است لینکهای سایر موجودیتها بهطور صریح و واضح ارائه شده باشند.
هنگام کار با دادههای ساختاریافته، سه گانه RDF، یک نمودار (یعنی نمودار دانش) را تعریف میکند که منابع موضوع و خود عبارت اصلی (URI) طبق شکل بالا دایرههای رنگی یا رأس نمودار هستند و دلایل و ویژگیها خطهای واصل درون نمودار هستند.
مشکل اصلی حالت نیمهساختاریافته در محاسبه امتیاز IR این است که اگر یک سند برای یک موضوع خاص طراحی نشده باشد و محتوای آن پراکنده باشد، امتیاز IR و رتبهی آن نسبت به سایر اسناد متنی میتواند به دلیل وجود بافتهای مختلف و وجود روابط واژگانی ضعیف و نامناسب و همچنین فاصله نامناسب بین واژگان در سند کاهش یابد.
برای افزایش امتیاز IR باید کلمات و واژگان مرتبط و مکمل در یک بخش یا سند استفاده شوند تا بافت متن بصورت یکپارچه، واضح و قابل فهم برای سیستم دربیاید.
در این بین استفاده از ویژگی ها و روابط موجودیت باعث افزایش ۵ تا ۲۰ درصدی امتیاز IR میشود. همچنین استفاده از اطلاعات مربوط به نوع موجودیت میتواند تا بهطور حتم امتیاز بازیابی اطلاعات را بهبود میبخشد.
حاشیه نویسی اسناد با موجودیتها می تواند ساختار را به اسناد بدون ساختار بیاورد، که میتواند به پر کردن پایگاههای دانش با اطلاعات جدید در مورد موجودیتها کمک کند.
استفاده از ویکیپدیا به عنوان چارچوب موجودیت سئو
ساختار صفحات ویکیپدیا
۱) عنوان
۲) متن مقدماتی یا lead
- لینکهای ابهامزدایی
- جعبه اطلاعات
- متن مقدماتی
۳) فهرست مطالب
۴) محتوای اصلی
۵) ضمایم و مطالب انتهایی
- منابع و یادداشتها
- لینکهای خارجی
- دستهبندیها
معمولاً مقالات ویکیپدیا با یک مقدمهی کوتاه یا Lead شروع میشوند که خلاصهی بسیار کوتاهی از محتوای کل است. تحریر و نگارش مقدمه باید طوری انجام شود که نظر کاربر را جلب کرده و او را علاقهمند به مطالعهی ادامهی مقاله کند.
جمله اول و پاراگراف آغازین، از اهمیت ویژهای برخوردار هستند. در نوشتن مقدمهی مقاله، در جملهی اول میتوان به تعریفی از موجودیت توصیف شده در مقاله پرداخت. همچنین در پاراگراف ابتدایی نیز تعریفی اجمالی از موضوع مقاله ارائه داد.
در این بین لینکها بسیار ارزشمند هستند؛ آنها علاوه بر هدایت کاربر به مقصد، روابط معنایی بین مقالات را نیز ثبت میکنند. همچنین انکر تکستها نیز یک منبع خوب از انواع نام موجودیتها هستند.
لینکهای ویکیپدیا علاوه بر دیگر کاربردهایی که دارند میتوانند برای کمک به شناسایی و ابهامزدایی ارجاعات موجودیتها در متن نیز استفاده شوند.
در ادامه خلاصهای از ویژگیهای اصلی صفحات ویکیپدیا که حاوی اطلاعات کلیدی ساختاریافته درباره موجودیتها هستند را برای شما آوردهام که به شرح زیر است:
- خلاصهای از واقعیتهای کلیدی در مورد موجودیت (جعبه اطلاعات)
- معرفی کوتاه و مختصر
- لینکهای داخلی (این امکان به ویراستاران داده میشود تا به اولین مفهوم یا ارجاع یک موجودیت لینک دهند.)
- درج تمامی مترادفات رایج برای یک موجودیت
- تعیین صفحه دستهبندی
- الگوی ناوبری
- منابع
- ابزارهای تجزیه ویژه برای فهم صفحات ویکی
- انواع مولتیمدیا
نحوهی بهینهسازی موجودیتها
در سئو نویسی و برای فهم و درک بهتر موتورهای جستجو از موضوع، رعایت یکسری از نکات اساسی و لازم است. نکاتی مثل:
- گنجاندن کلمات مرتبط از لحاظ معنایی با موضوع در یک صفحه
- استفادهی زیاد از کلمات و واژگان در یک صفحه
- ساماندهی مفاهیم در یک صفحه
- گنجاندن دادههای ساختارنیافته، نیمه ساختاریافته و ساختاریافته در یک صفحه
- افزودن جفتهای موضوع-گزاره-شیء (SPO)
- ارائه اسناد وب در یک سایت که مانند صفحات یک کتاب عمل میکنند
- سازماندهی اسناد وب در سطح صفحه و وبسایت
- گنجاندن مفاهیم و ویژگیهای شناخته شده از موجودیت در سند
وقتی شما یک عبارت را جستجو میکنید، موتور جستجوگر عبارت را با توجه به گزارش جستجوهای سابق شما و سایر قسمتهای زمینهای تحلیل میکند و بر اساس آنها نتایج مربوطه را به شما ارائه میدهد.
به همین دلیل ممکن است یک عبارت جستجوی یکسان از سوی دو کاربر مختلف، نتایج متفاوتی داشته باشد.
کاربران میتوانند با یک درخواست کاملاً یکسان، قصد و نیت متفاوتی داشته باشند. برای مثال فرض کنید شما در چند وقت اخیر راجب خرید و فروش اجناس و راههای فروش جنس دست دوم جستجو کردهاید و من نیز راجب ساختمان، و نقاشی ساختمان جستجو کردهام.
وقتی هر دوی ما کلمهی دیوار را جستجو کنیم، موتور جستجو بر اساس سابقهی جستجوهای ما نتایج متفاوتی را نشان میدهد.
مثلاً در صدر لیست نتایج شما، پلتفرم خرید و فروش دیوار نشان داده میشود و برای من در صفحهی نتایج وبهایی که در آن به تعریفی از دیوار به معنای حایل و… پرداختهاند به نمایش در میآیند.
بنابراین تحلیل قصد و نیت کاربر در کنار سایر عوامل متن برای یک درخواست یکسان میتواند منجر به نمایش نتایج شخصیسازی شده شود.
اگر صفحهی شما هر دو نوع قصد و نیت را پوشش دهد، رتبهبندی بهتری کسب میکند و میتوانید از ساختار پایگاههای دانش برای هدایت الگوهای پرسوجوی (query-intent) خود استفاده کنید. بهطور کل پوشش تمامی اهداف و قصد کاربران در یک صفحه، باعث بهبود رتبهی صفحه میشود.
قسمتهایی مثل «دیگران همچنین پرسیدهاند»، «دیگران همچنین جستجو کردهاند» و «تکمیل خودکار» در موتورهای جستجو، ارتباط معنایی با درخواست جستجوی کاربر دارند و به جستجوی عمیقتر دربارهی موضوع و هدایت کاربر به سمت جنبه دیگری از موضوع کمک میکنند.
این ویژگیها با توجه به ارتباط معنایی با درخواست کاربر به او کمک میکنند تا جستجوی خود را عمیقتر و یا در ابعاد دیگری انجام دهد.
حال شاید با خود بگویید بعد از دانستن این موارد چگونه بهینهسازی را انجام دهیم؟ در ادامه با من همراه باشید تا جواب سوال خود را بگیرید.
باید سعی کنید محتوایی که دربارهی یک عبارت ارائه میدهید اکثر اهداف جستجوی آن عبارت را پوشش دهد. تا وبسایت شما بتواند شامل تمام اهداف احتمالی جستجو برای مجموعه یا خوشه مربوطه باشد. پایه و اساس خوشهبندی، سه نوع شباهت است:
- شباهت واژگانی
- شباهت معنایی
- شباهت کلیک
پوشش موضوع
برای اینکه یک محتوای جامع راجع به یک موضوع بنویسید، میتوانید طبق دستورالعمل زیر پیش بروید:
- توضیح موضوع
- ایجاد فهرستی از ویژگیها و خصوصیات
- اختصاص بخشی به هر یک از ویژگیها و خصوصیات
- لینکدهی هر بخش به مقالهای که کاملاً به آن موضوع اختصاص دارد
- شناسایی مخاطبان هدف و تعیین تعاریف
- بررسی نکاتی که باید مورد توجه قرار گیرند
- بیان فواید و مزایا
- بیان مزایای تکمیلی
- توضیح عملکرد موضوع
- چگونگی دستیابی به موضوع
- نحوه انجام آن
- بیان اینکه چه کسانی قادر به انجام آن هستند؟
- لینکدهی مجدد به همه دستهبندیها

Salience Score امتیاز یا نمرهای است که گوگل به کمک یکسری ابزار به محتوا اختصاص میدهد و یکی از ملاکهایی است که نشان میدهد محتوا از نظر گوگل چگونه است.
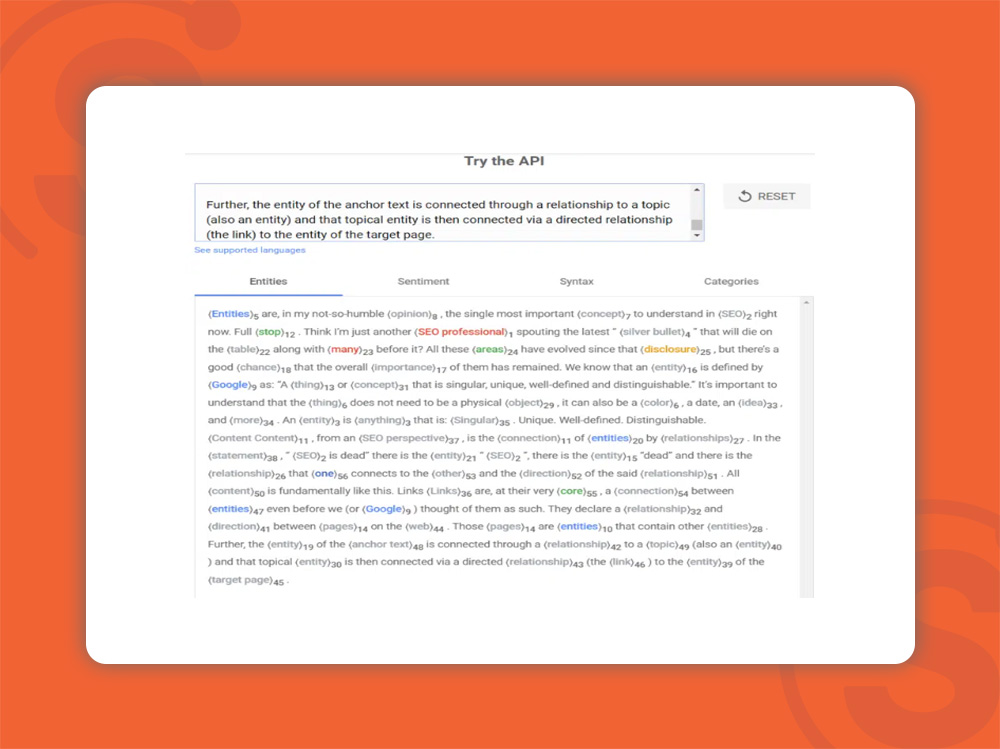
مثال بالا از یک مقاله در مورد موجودیتها که در سال ۲۰۱۸ نوشته شده برگرفته شده است.
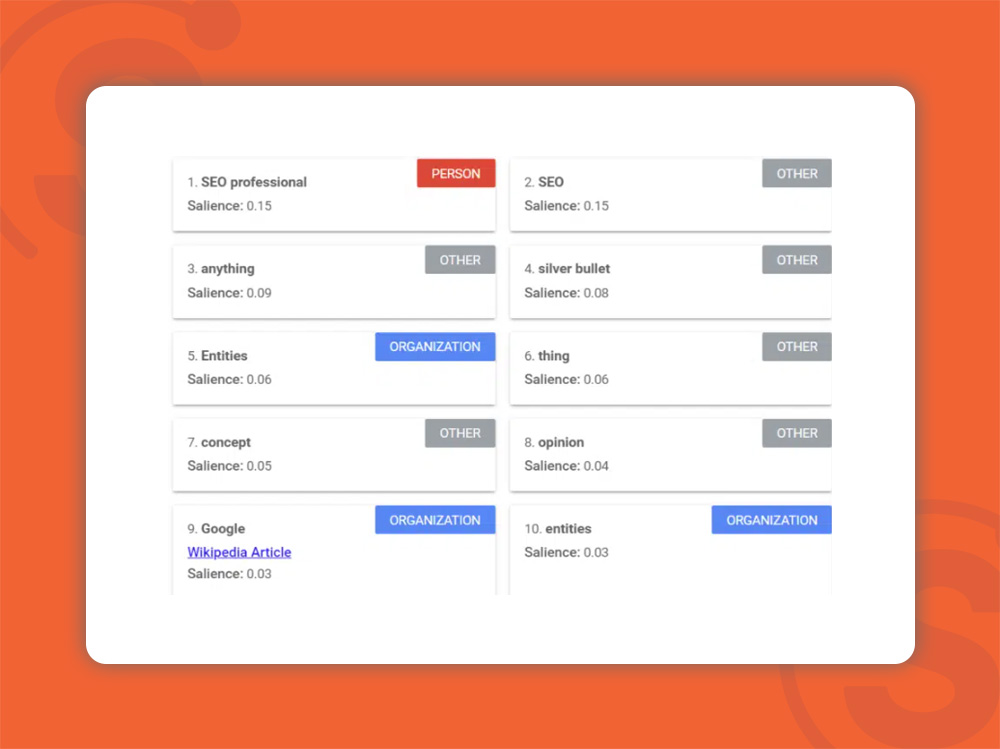
نتایج بالا به کمک ابزار Google Cloud’s Natural Language API بدست آمده است. در این مثال، موجودیتهای فرد (person)، سازمان (organization) و سایر (other) قابل مشاهده هستند.
هنگامی که راجب یک موجودیت در محتوای خود صحبت میکنید هر واژه، جمله و یا پاراگرافی که به کار میبرید و مینویسید اهمیت زیادی دارد.
هر یک از این واژهها و جملات میتواند فهم و درک گوگل از موضوع را تغییر دهد.
زمانی که میخواهید مطمئن شوید گوگل عبارت را همانطور که میخواهید درک میکند یا نه، بهتر است از ابهامزدایی بهره بگیرید.
به این صورت که یک یا دو پاراگراف به محتوای خود اضافه یا از آن کم کنید و یا به صورتهای مختلف آن را اصلاح کنید تا ببینید در کدام صورت امتیاز Salience بالاتری کسب میکند.
این را بدانید همواره باید سعی کنید ابهام زبان و کلمات را برای گوگل رفع کنید.
ملاکهای ابهامزدایی بصورت زیر است:
- میزان اهمیت موجودیتها و واژههایی که در ابتدا به آنها اشاره میکردند نسبت به تغییرات جدید
- میزان شباهت معنایی موجودیت و متنی که در پیرامون آن ذکر شده
- میزان انسجام کلی بین تمامی اقدامات صورت گرفته و موجودیت ذکر شده
در ابهامزدایی محتوای نوشته شده، استفاده از Schema یکی از محبوبترین روشها است. در این روش موجودیتها در وبلاگ به منابع و پایگاه دانش ساختاریافته لینک میشوند.
لینک دادن موجودیتها در متن ساختار نیافته به یک پایگاه دانش ساختار یافته، بهطور چشمگیری توانایی کاربران را در استفاده از اطلاعات افزایش میدهد.
برای مثال وقتی در حال خواندن یک محتوا یا سند هستید میتوانید با کلیک بر روی موجودیتها، اطلاعات بیشتری در مورد آنها به دست بیاورید و به آسانی به موجودیتهای مرتبط دسترسی پیدا کنید.
همچنین میتوانید هنگام نگارش محتوا، انتیتیهای موجود در متن را شناسایی و برچسبگذاری کنید تا در مراحل بعدی مانند بازیابی اطلاعات و نمایش نتایج به کاربر مورد استفاده قرار گیرند و بهطور کلی باعث تعامل بهتر کاربر با نتایج جستجو شوند.

در اینجا میتوانید محتوای سوالات متداول که با استفاده از Schema برای موتور جستجوی گوگل ساختاردهی و برچسبگذاری شدهاند را ببینید.
در این مثال Schema مواردی چون توصیفی از متن، شناسه و اعلام موجودیت اصلی صفحه را ارائه میدهد.
یادآوری: گوگل برای درک بهتر ساختار اطلاعات موجود در یک صفحه، نیاز به استفاده از عناوین یا تگ هدینگ H1 تا H6 دارد.
با استفاده از Schema به گوگل کمک میکنیم تا بهتر بتواند ارتباط بین متن یک صفحه و پایگاه دادههای ساختاریافتهی مرتبط را تشخیص دهد.
همچنین Schema با جمعآوری نامهای جایگزین و مترادف برای موجودیتها، قدرت تشخیص گوگل در شناسایی روابط معنایی بین کلمات متفاوت اما مرتبط با یک موجودیت را میدهد.
در واقع شما با بهینهسازی اسکیما، NER یا همان تشخیص موجودیت (entity recognition) که با نامهای entity identification و entity extraction و یا entity chunking نیز شناخته میشود را بهینهسازی میکنید که باعث میشود الگوریتمهای شناسایی و استخراج موجودیتها بهتر عمل کند و موجودیتها دقیقتر شناسایی شوند.
یکی از ایدههای این بهینهسازی، ابهامزدایی از موجودیت، ویکیسازی و لینکدهی به موجودیت است.

در کتاب Entity-Oriented Search آمده است:
«ویکیپدیا با ارائه فهرست جامعی از موجودیتها همراه با منابع ارزشمندی مانند لینکها، دستهها، صفحات تغییر مسیر و ابهامزدایی به شناسایی و ابهامزدایی موجودیتها بسیار کمک کرده است.»
چگونه فراتر از پیشنهادات ابزارهای سئو پیش برویم؟
من در دوره سئو سفینه توضیح دادهام که متاسفانه افراد تازه کار در سئو از ابزارهای درون صفحهای (on-page) برای بهینهسازی محتوای خود استفاده میکنند. قاعدتاً هر کدام از این ابزارها توانایی محدودی در شناسایی محتوای برتر دارند.
در بیشتر موارد ابزارهای on-page تنها نتایج برتر SERP را جمعآوری میکنند که بر اساس آن تنها میتوانید محتوای خود را شبیهسازی کنید.
این را باید به خاطر داشته باشید که گوگل به دنبال همان اطلاعات بازنویسی شده نیست. شما میتوانید کارهایی که دیگران انجام میدهند را کپی کنید و عیناً آنها را در محتوای خود بیاورید، اما دیگر نباید دنبال برتر شدن باشید. چون کلید برتری، خاص و منحصر به فرد بودن اطلاعات است.
اگر محتوایی را که ارائه میدهید کل موضوع را پوشش دهد و سطح جدیدی از اطلاعات مربوط به موجودیت را ارائه دهد، پس از مدتی گوگل محتوای جدید را بررسی میکند و با مطالب جدیدی که شما آنها را عنوان کردهاید پایگاه دانش مربوط به آن موجودیت را بروز میکند.
در نتیجه با ارائهی این مطالب و بهبود شناسایی موجودیت وبسایت شما برای گوگل یک مرجع شناخته میشود که این تغییرات بروز شده را به وبسایت شما به عنوان منبع اولیه ارجاع میدهد.
بهطور کلی شما با ارائهی یک محتوای ارزشمند و کامل در رابطه با یک موضوع خاص میتوانید وبسایت خود را در آن حوزه به عنوان یک مرجع معتبر شناخته کنید.
گوگل نیز با تجزیه و تحلیل محتوا اطلاعات جدید و با ارزشی که توسط شما ارائه میشود را شناسایی میکند.
اگر این استراتژی را به همین منوال و در رابطه با موضوعات دیگر ادامه دهید میتوانید به یک مرجع بزرگ نه بر اساس اتوریتی دامنه، بلکه بر پایه پوشش عمیق موضوعی تبدیل شوید.
بیایید برایتان یک مثال بزنم. برای مثال عبارت فلای فیشینگ را در ویکیپدیا سرچ میکنیم و اطلاعاتی مانند گونههای ماهی، تاریخچه، خواستگاه، توسعه، پیشرفتهای تکنولوژیکی، گسترش، روشهای ماهیگیری، ریختهگری، ریختهگری ماهیگیری، صید ماهی قزلآلا با مگس، تکنیکهای فلای فیشینگ، ماهیگیری در آب سرد، صید ماهی قزلآلا با مگس خشک، پورهگیری برای قزلآلا، صید قزلآلا، رهاسازی قزلآلا، ماهیگیری با مگس آب شور و… بالا میآید.
در حالی که این صفحه نمای کلی و عالی از موضوعات را ارائه میدهد اما میتوانیم ایدههای دیگری که از موضوعات مرتبط از نظر معنایی میآیند را نیز اضافه کنیم.
برای مبحث «ماهی» میتوانیم چندین موضوع دیگر از جمله ریشهشناسی، تکامل، آناتومی و فیزیولوژی، ارتباطات ماهی، بیماریهای ماهی، حفاظت و اهمیت برای انسان را نیز اضافه کنیم.
شما میتوانید با تکیه بر تفکر خلاقانه انسانی، بر تغییرات هدف جستجو متمرکز شوید و آنها را هدف قرار دهید.
برای مثال ببینید آیا کسی آناتومی ماهی قزلآلا را با اثربخشی برخی از تکنیکهای ماهیگیری مرتبط کرده است؟ آیا یک وبسایت ماهیگیری همه گونههای ماهی را پوشش داده است و در عین حال انواع تکنیکهای ماهیگیری، میلهها و طعمهها را به هر ماهی ارتباط میدهد یا خیر.
شما باید بتوانید ببینید که چگونه میتوانید موضوع را گسترش دهید و اینها را باید هنگام برنامهریزی کمپین محتوا در نظر داشته باشید.
سعی کنید از مطالب تکراری استفاده نکنید بلکه منحصر به فرد باشید و ارزش بیشتری به مطالب موجود اضافه کنید.


